NLP Adversarial Robustness
This walkthrough will cover how to test your NLP model’s robustness to adversarial attacks. To run the demo, navigate to the Adversarial NLP Colab Notebook and follow the instructions or reference the tutorial below.
User persona and problem statement
You are the AI Risk Officer at a Consumer Social Company. The NLP team has been tasked with implementing a text classification model to predict the top-level “sentiment” of posts on the app. These predictions will later be consumed by multiple models throughout the company, such as recommendation, lead prediction, and the core advertisement models. You want to verify your models are sufficiently robust to adversaries seeking to exploit model vulnerabilities and boost content that your user base does not actually like.
In this Notebook Walkthrough, we will review our core product of AI Stress Testing of NLP models in an adversarial setting. RIME AI Stress Testing allows you to test any text classification model on any dataset. In this way, you will be able to quantify your model’s vulnerability to attacks and noisy data.
Your team’s NLP models are fine-tuned from state-of-the-art transformer models found on Hugging Face’s Model Hub 🤗. In particular, you have chosen to fine-tune a DistilBERT on data similar to the Stanford Sentiment Treebank dataset for a lightweight yet performant model.
To begin, please specify your RIME cluster’s URL and personal access token.
# set these before beginning!
CLUSTER_URL = '' # e.g., rime.<name>.rbst.io
API_TOKEN = ''
%pip install rime-sdk &> /dev/null
%pip install seaborn
Create the Image
First, we connect to the RIME cluster using the URL and API Token. To connect with
Hugging Face, we create a managed image with the transformers and datasets
dependencies installed.
from rime_sdk import Client
image_name = "adversarial_nlp"
# connect to your cluster
rime_client = Client(CLUSTER_URL, api_key=API_TOKEN)
# Specify pip requirements for the run. Some models require additional dependencies.
requirements = [
rime_client.pip_requirement("transformers"),
rime_client.pip_requirement("datasets"),
# Uncomment if you need sentencepiece
# rime_client.pip_requirement("sentencepiece"),
]
if not client.has_managed_image(image_name, check_status=True):
# e.g., if the image build job failed
if client.has_managed_image(image_name):
client.delete_managed_image(image_name)
# Start a new image building job
builder_job = client.create_managed_image(image_name, requirements)
# Wait until the job has finished and print out status information.
# Once this prints out the `READY` status, your image is available for use in stress tests.
builder_job.get_status(verbose=True, wait_until_finish=True, poll_rate_sec=20)
Create a Project
A project stores this and other future adversarial robustness stress test run results.
description = (
"Evaluate the robustness of text classification models"
" against adversarial attacks. Demonstration uses the"
" SST-2 dataset (https://huggingface.co/datasets/sst2)"
" and a fine-tuned version of the DistilBERT model"
" (https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english)."
)
project = client.create_project(
name="NLP Adversarial Robustness Demo",
description=description,
model_task="MODEL_TASK_MULTICLASS_CLASSIFICATION"
)
Register model and datasets
Register the model and datasets used in this test with RIME.
from datetime import datetime
dt = str(datetime.now())
model_id = project.register_model(f'model_{dt}', model_config={
"hugging_face": {"model_uri": "distilbert-base-uncased-finetuned-sst-2-english"}
})
def _register_dataset(split_name):
data_info = {
"connection_info": {
"hugging_face": {
"dataset_uri": "sst2",
"split_name": split_name,
},
},
"data_params": {
"label_col": "label",
"text_features": ["sentence"],
"sample": True, "nrows": 100
},
}
return project.register_dataset(f'{split_name}_datset_{dt}', data_info)
ref_dataset_id = _register_dataset("train")
eval_dataset_id = _register_dataset("validation")
Launch a stress test run
stress_test_config = {
"run_name": "DistilBERT Adversarial Robustness",
"data_info": {
"ref_dataset_id": ref_dataset_id,
"eval_dataset_id": eval_dataset_id,
},
"model_id": model_id,
"test_suite_config": {
"categories": [
{"name": "Adversarial", "run_st": True, "run_ct": True}
],
"individual_tests_config": {"global_exclude_columns": ["idx"]},
},
"run_time_info": {
"custom_image": {
"managed_image_name": 'arxiv_image'
}
}
}
stress_job = client.start_stress_test(
stress_test_config, project.project_id
)
stress_job.get_status(verbose=True, wait_until_finish=True)
Review Adversarial Stress Test Run
Now that the test run is complete, we can check out the results in the RIME web UI.
test_run = stress_job.get_test_run()
test_run
Query Results
Alternatively, we can query the test case results to identify model vulnerabilities.
result_df = test_run.get_result_df()
result_df.head()
Test Severity: Let’s plot some of the results. First, let’s check the severity distribution of attack tests.
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style="white")
severity_cols = [col for col in result_df.columns if 'severity_counts' in col.lower()]
severity_counts = result_df[severity_cols].iloc[0]
plt.pie(severity_counts, labels=severity_cols)
plt.show()
Reviewing Test Case Results
Next, let’s look at the results by attack type.
test_cases_df = test_run.get_test_cases_df(show_test_case_metrics=True)
test_cases_df.head()
fig = plt.figure(figsize=(10,10))
test_type_pass_rates = {name: (batch_df['status'] == 'PASS').sum() / len(batch_df) for name, batch_df in test_cases_df.groupby("test_batch_type")}
sns.barplot(y=list(test_type_pass_rates.keys()), x=list(test_type_pass_rates.values()), orient='h')
plt.xlabel('Pass Rate')
plt.ylabel('Test Type')
plt.show()
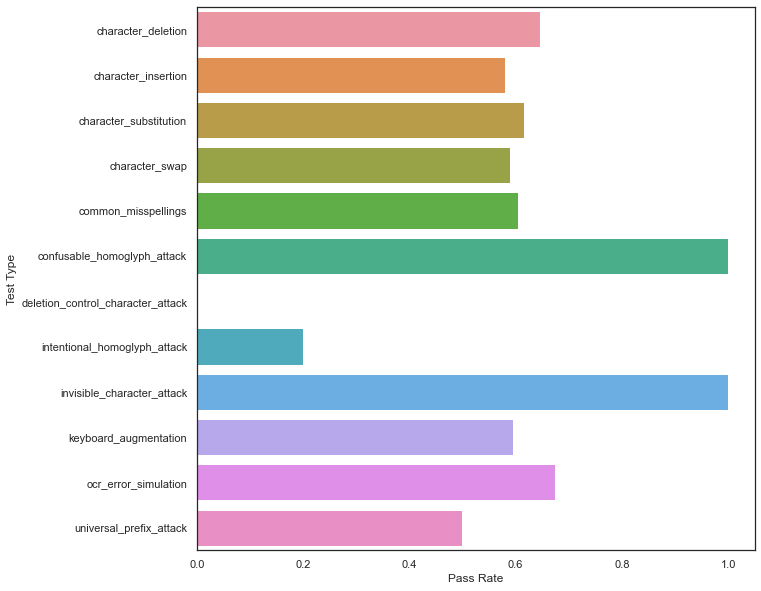
It’s evident that while this model is fairly robust to homoglyph-type attacks, it frequently fails to withstand character-level perturbations, indicating that additional data augmentation and/or a data sanitation pipeline should be applied before this model goes into production! One way to add additional augmented data to your training problem is through querying the results:
import pandas as pd
def filter_rows(text_series: pd.Series, label_series: pd.Series) -> pd.DataFrame:
filter_indices = ~text_series.isna()
return pd.DataFrame({'Augmented': text_series[filter_indices], "Labels": label_series[filter_indices]})
failed_df = test_cases_df[test_cases_df['severity'] == 'SEVERITY_ALERT']
# attacks examples
perturbed_text_col = [col for col in test_cases_df.columns if col.endswith('perturbed_sentence')][0]
class_col = [col for col in test_cases_df.columns if col.endswith('original_class')][0]
perturbed_df = filter_rows(failed_df[perturbed_text_col], failed_df[class_col])
augmented_df = pd.concat([
perturbed_df,
# transformed_df,
], ignore_index=True)
augmented_df.head()